A unified framework for mutual reinforcement of motion and geometry,
Zero-shot motion segmentation with 3D spatio-temporal information priori-guided,
Enhanced 4D renconstruction pipeline
Qulitative Results of Motion Segmentation

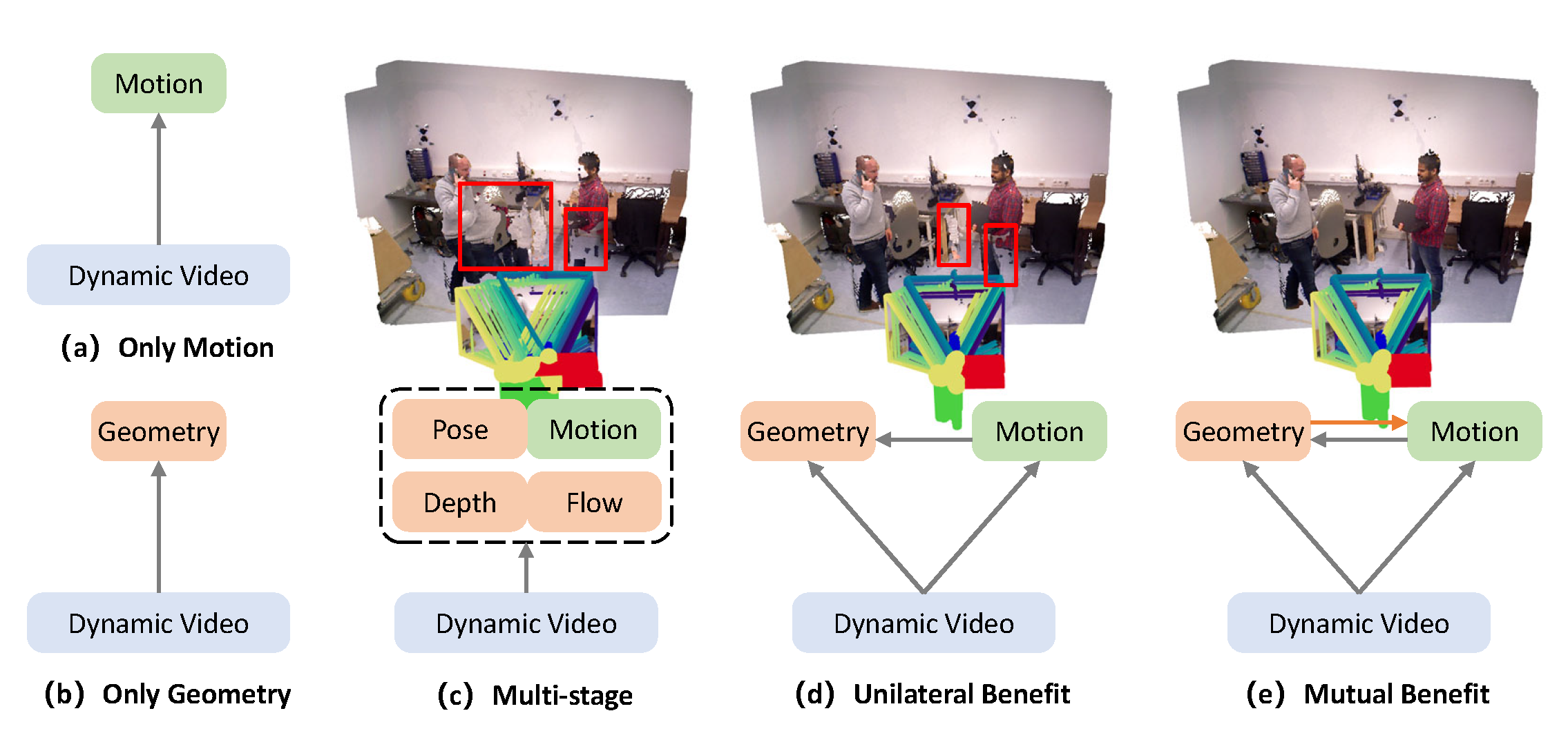
The estimation of both motion and geometry from dynamic scenes is an open and underconstrained problem in computer vision. Constrained by the limited availability of co-labeled data, current end-to-end methods consider motion segmentation and geometry estimation as two independent tasks. Existing approaches typically use motion segmentation to facilitate geometric alignment. However, geometry estimation also offers valuable information that can enhance motion segmentation.
This paper proposes a framework that mutually benefits zero-shot motion segmentation and consistent geometric reconstruction. Specifically, 3D spatio-temporal priors are extracted from a geometry-first 4D reconstruction model to guide generalizable motion segmentation. A Dual-Dimension Multi-path Information Fusion (D$^2$MIF) module is designed to fuse complementary 3D and 2D information at multiple scales through a recursive refinement mechanism, thereby improving zero-shot segmentation in complex dynamic scenes include background distraction and object articulations. Subsequently, the refined motion segmentation mask is utilized to more accurately separate the dynamic foreground from the static background during alignment, thus improving the geometric consistency of the 4D reconstruction. The resulting framework produces an integrated output for several downstream video-specific tasks while maintaining efficiency. Experimental results validate the mutual benefits of the proposed framework and its superiority in downstream 4D reconstruction tasks. The generalizability of the motion segmentation model is confirmed through a series of zero-shot evaluations.
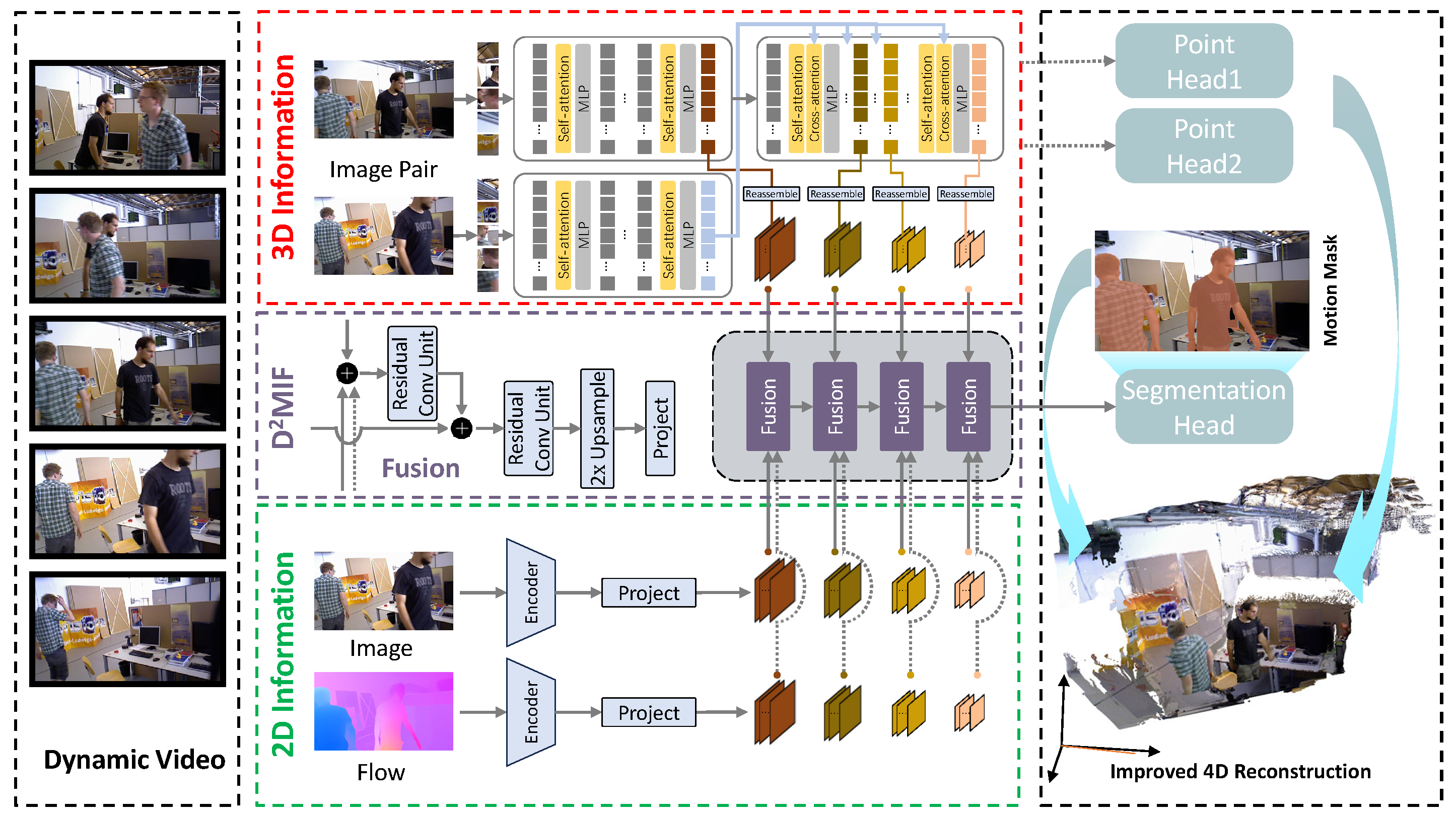
Overview. Overview of the 3D spatio-temporal information priori-guided motion segmentation framework. We feed time-dependent image pairs into the 4D reconstruction model to extract 3D spatio-temporal priors. The D^2MIF (Dual-Dimension Multi-path Information Fusion) module then integrates 2D and 3D spatio-temporal information from multiple paths and recursively fuses spatio-temporal features to generate dynamic segmentation masks. Additionally, our motion segmentation model is incorporated as a plug-and-play sub-module within the existing 4D scene reconstruction pipeline, thereby enhancing reconstruction quality through the use of refined dynamic mask.
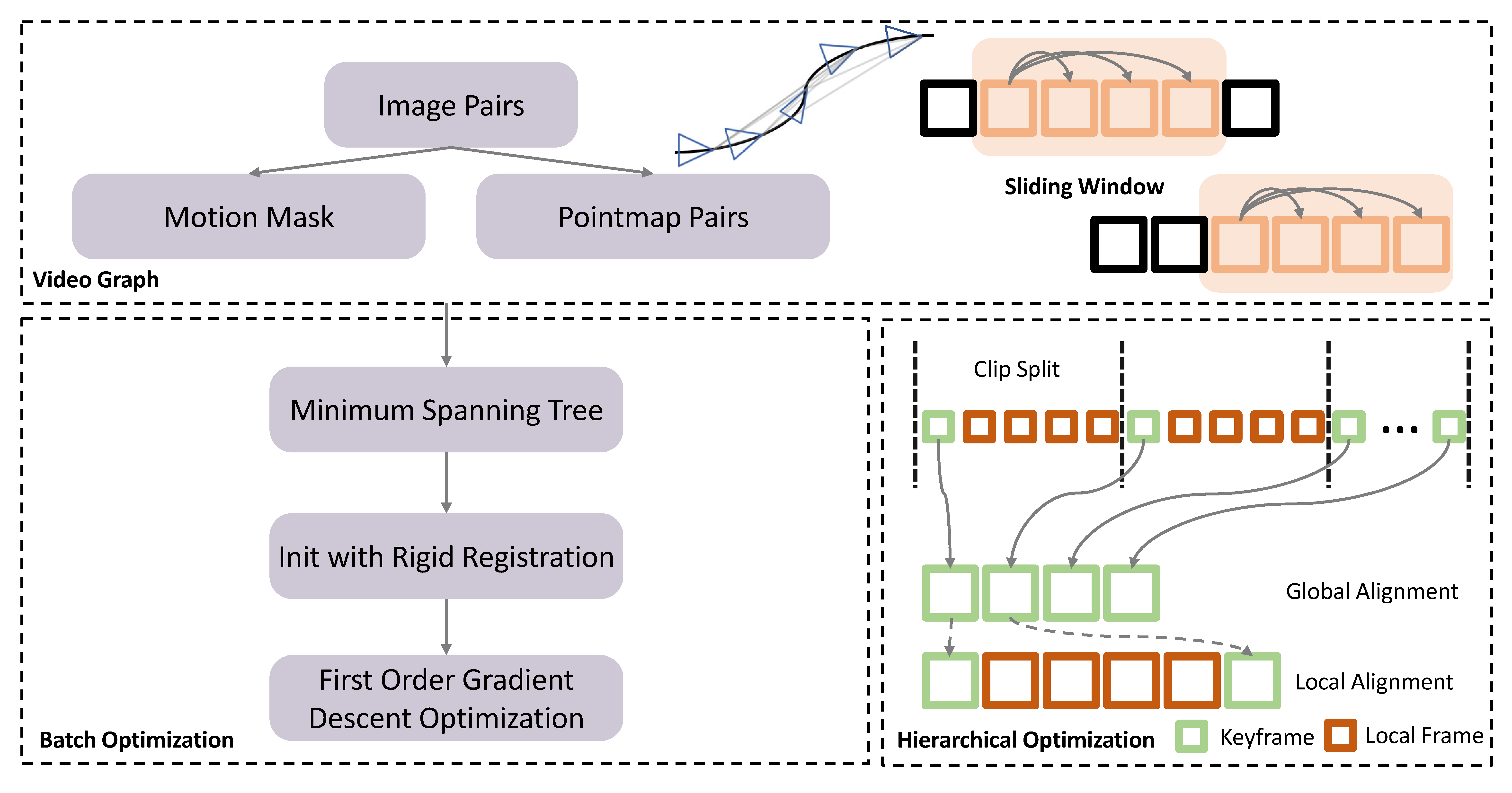
Schematic of enhanced 4D renconstruction pipeline. We construct video graphs from time-continuous video frames using a sliding window approach to form image pairs. For each pair, we predict motion segmentation masks and local pointmaps (top). During batch optimization, an initial globally aligned pointmaps is generated using a Minimum Spanning Tree and rigid registration, followed by iterative optimization via first-order gradient descent (left bottom). Additionally, we optimize the keyframe strategy to enhance global scale consistency in hierarchical optimization (right bottom).